This post is actually a continuation post for TEMPDB – the most important system database in SQL Server which trying to cover one of the important usage of TEMPDB in SQL Server. Some operations in SQL Server uses TEMPDB internally to improve the performance of the operations. It may not be fully aware for the users, but we can understand the usage of tempdb using the below query.
--Query to understand the internal usage of TEMPDB
select
reserved_MB=(unallocated_extent_page_count+
version_store_reserved_page_count+
user_object_reserved_page_count+
internal_object_reserved_page_count+
mixed_extent_page_count)*8/1024. ,
unallocated_extent_MB =unallocated_extent_page_count*8/1024.,
internal_object_reserved_page_count,
internal_object_reserved_MB =internal_object_reserved_page_count*8/1024.
from sys.dm_db_file_space_usage
Few of operations as below:
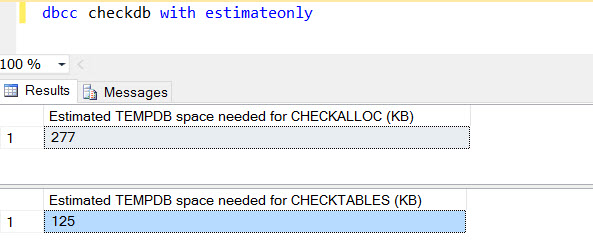
1. DBCC CHECKDB/CHECKALLOC
DBCC CHECKDB/CHECKALLOC are using TEMPDB space for creating internal database snapshot to perform the operation. This is to efficiently avoid the locking behavior on database to obtain the consistency check. DBCC CHECKDB and CHECKALLOC has an option to estimate the usage of TEMPDB by providing ESTIMATEONLY option as below. Please note, this is an estimated value, may not be the correct one, however, this can be a good indication to estimate the space required for the operation. This can be used to make sure the TEMPDB drive has enough space to run on DBCC operations for large databases.
2. SORT operations can spill over to TEMPDB
When a query is executed, SQL optimizer will choose the plan already created if prsent or will create a new plan based on cost based algorithms. When optimizer creates a plan, SQL optimizer/relational engine will identify the right operator for the plan to execute the queries and it estimates the memory required to execute the query. This plan will be used for further execution. If the estimation is not happening correctly because of wrong statistics or parameters used while creating the plan is returning less number of records, the estimated number of records will be deviating from the actual number of records while executing the query. In such scenario, the memory granted for the execution may not be sufficient for the execution.
If SORT operator needs more memory to sort the data , other words, the memory granted is not sufficient to do the sorting, it will spill over to TEMPDB. This will have a performance impact for the query execution. The spill over to TEMPDB can be observed in the profiler as SORT warnings(below).

In the above snapshot, we can see Sort warnings in profiler with Event Subclass as single or multiple. Whenever the sort operation spills to tempdb, SQL Server raises the ‘Sort Warnings’ event and it takes single or multiple passes to tempdb.
As mentioned, Sort warnings or spilling to TempDB will have some detrimental impact on the query performance, we need to identify those queries and avoid if possible. Through profiler, we may not understand the query is being caused the Sort Warnings, but, we need to identify from the cached plan or by setting up Extended events to capture the Sort warnings.
Once we identified the query caused Sort Warning, the easiest solution would be re-write the query in a manner to avoid the sorting. I have seen queries with CTE using the ORDER BY even though the order by is not required specifically. Try to use ORDER BY genuinely to avoid performance issues. At the same time, it may not be easy for all cases to avoid the ORDER BY completely. Similar scenario, we may need to evaluate adding a supporting index or modify the existing indexes to avoid, but again, this needs more careful and clear understanding of code and index usage. If you are well aware of the reason for Sort warnings are due to incorrect statistics, you can update the stats or use the solutions to avoid the parameter sniffing(As the objective of this post is not going to explain the parameter sniffing, this post does not cover the topic now.).
3. Worktables/intermediate temp objects due to spooling/hash joins/aggregate Operations
Spools are special operators created by SQL optimizer to improve the performance of a query. A spool operator is not an independent operator,but a supporting operator for another operator like clustered index scan, Table scan or even Constant scan. A spool operator reads and stores intermediate “operated” data into TEMPDB from another operator, there by, increasing the performance of the query.
In the below snapshot, we can observe that the spool operator stores the data from the input, here its nothing but constant scan into a temporary tables to avoid multiple rewinds.
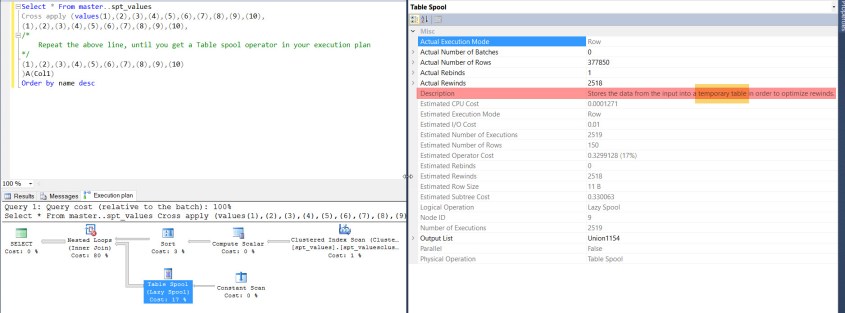
There are totally five types of spool operators – Eager, Lazy, Table, RowCount and Non-Clustered Index spools. All spool operators will store the data into TEMPDB, however, it may be different the way it behaves. Please explore further on the topic to know more details.
Hope you enjoyed this post, please post your feedback/thoughts in the comments.




