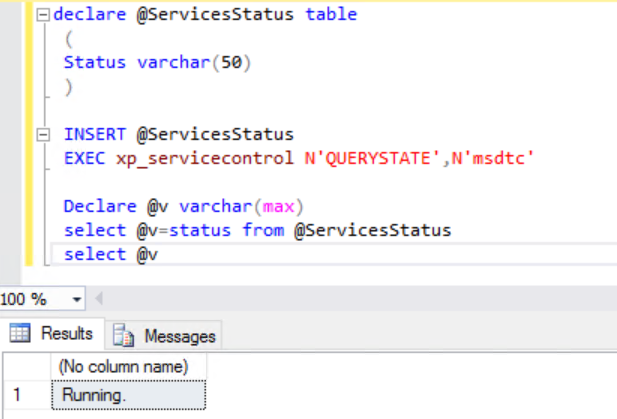
Using ring buffers
DECLARE @ts_now BIGINT = (SELECT cpu_ticks / ( cpu_ticks / ms_ticks )
FROM sys.dm_os_sys_info WITH (nolock));
SELECT TOP(256) sqlprocessutilization AS [SQL Server Process CPU Utilization],
systemidle AS [System Idle Process],
100 - systemidle - sqlprocessutilization AS [Other Process CPU Utilization],
Dateadd(ms, -1 * ( @ts_now - [timestamp] ), Getdate()) AS [Event Time]
FROM
(SELECT
record.value('(./Record/@id)[1]', 'int') AS record_id,
record.value('(./Record/SchedulerMonitorEvent/SystemHealth/SystemIdle)[1]', 'int') AS [SystemIdle],
record.value('(./Record/SchedulerMonitorEvent/SystemHealth/ProcessUtilization)[1]', 'int') AS [SQLProcessUtilization],
[timestamp]
FROM (SELECT [timestamp],
CONVERT(XML, record) AS [record]
FROM sys.dm_os_ring_buffers WITH (nolock)
WHERE ring_buffer_type = N'RING_BUFFER_SCHEDULER_MONITOR'
AND record LIKE N'%%') AS x
) AS y
ORDER BY record_id DESC
OPTION (recompile);
ring buffers is a good way to get the CPU utilization as above. Please note, the above code is being used heavily by many DBAs, I do not really know who is the author of the above script, however, would like to give full credit to the author who drafted it.
Using perfmon
Performance monitor (perfmon) is a built-in tool in windows server to track the system performance and other data points. We can configure perfmon to run on scheduled manner and collect the information as per the requirement. Most of the production servers will be enabled with perfmon to track the performance and it has no or less impact on the server.
Once the data is collected, you can even look at the data through graphana or kibana which would provide us a good data representation.
Using open source monitoring tools
There are many open source monitoring tool in the market which can be used to get the information from server. Few of the tools are explained in the link https://geekflare.com/best-open-source-monitoring-software/